Welcome to the SRP Forum! Please refer to the SRP Forum FAQ post if you have any questions regarding how the forum works.
garbagecollect

Anyone have any recommendations for implementing garbagecollect in this environment?
I've just had our system fall over with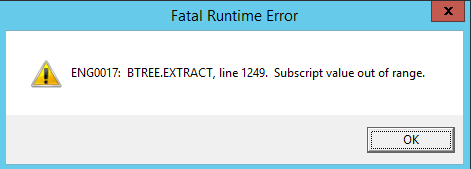
A restart of the socketserver and everything is good again but I think this is the second time in about a fortnight.
Last time there was no messages of value, just out of memory errors. This time there was lots of those too plus this little nugget so that's a little better for troubleshooting.
I think flushing and garbagecollecting might help prevent this moving forward but I don't want to be doing one every request if I don't have to.
Any suggestions?
I've just had our system fall over with
A restart of the socketserver and everything is good again but I think this is the second time in about a fortnight.
Last time there was no messages of value, just out of memory errors. This time there was lots of those too plus this little nugget so that's a little better for troubleshooting.
I think flushing and garbagecollecting might help prevent this moving forward but I don't want to be doing one every request if I don't have to.
Any suggestions?
Comments
Before you reply back, please check your copy of HTTP_Services and let me know if you have a ClearSettings service.
sorry for the confusion.
Yes I have a clearSettings service.
The mixed message was because I think (but I don't know) that the garbagecollect might be
- extra overhead I don't want happening too often if I can avoid it and
- may clear caching that is advantageous for the app to have around
With that in mind I was just wondering if there was an existing means by which to say flush every nth request or something similar.Of course my concerns may be overstated and I should just throw a garbagecollect in the mcp routine and be done with it.
Of course, there's also the possibility that it will do absolutely nothing to address the primary issue anyway.
But, as you say, it might not address the underlying issue.
Yeah...I was about to make a comment along those lines. You want to keep each request as stateless as possible. To that end, this is why I have the ClearSettings and the CleanUp services being called at the end.
//---------------------------------------------------------------------------------------------------------------------- // ClearSettings // // @@DEFINE_SERVICE(ClearSettings) // // Clears all of the global common variables used to track header names, values, and the status settings. This will // typically only be called within HTTP_MCP when the response is finished and sent back to the OECGI. //---------------------------------------------------------------------------------------------------------------------- ClearSettings: Request@ = '' RequestHeaderFields@ = '' RequestHeaderValues@ = '' ResponseHeaderFields@ = '' ResponseHeaderValues@ = '' ResponseStatusCode@ = '' ResponseStatusPhrase@ = '' ResponseBody@ = '' ResponseBodyIsBinary@ = '' SelfURL@ = '' QueryFields@ = '' QueryValues@ = '' Memory_Services('ReleaseHashTable') returnProbably time I should update some things.
So the problem I need solving is how to prevent the engines maxing out the machines memory. The config is set to use ten engines and they all fire up relatively quickly after starting and then stay running as even if there are no direct user requests, there is a task that fires requests every minute so the engines never really become idle enough to shut down.
Everything starts efficiently but over a period of time (days not weeks) the memory usage rises and rises and once it hits about 95% things start to fall over. I need a way to prevent that from happening.
At the moment, I'm simply monitoring and every couple of days as it starts getting closer to the danger point, I restart the socketserver which basically resets everything.
At the moment it's not yet running as a service and granted if it was we could create some automated task to restart the service at regular intervals but I feel that too would just be a bandaid remedy and not a real solution.
I'd prefer it if there was a means of managing the memory without the need to take the service offline even if it is only temporary. I feel like there must be a way, I just don't have any idea what that is.